

Lồng tiếng bằng AI (AI Dubbing) hoạt động với ba bước chính: Tạo nội dung phụ đề, Dịch phụ đề và Chuyển văn bản thành giọng nói lồng tiếng. So với TTS thông thường, hệ thống chuyển đổi phụ đề sang giọng nói thường cần thêm các bước xử lý phức tạp hơn rất nhiều.
1. Tạo phụ đề từ giọng nói
Để tạo nội dung phụ đề từ âm thanh, chúng ta cần bắt đầu bằng việc tách giọng nói từ video, tiếp theo là nhận diện nội dung văn bản từ giọng nói và cuối cùng là tạo ra các phụ đề phù hợp.
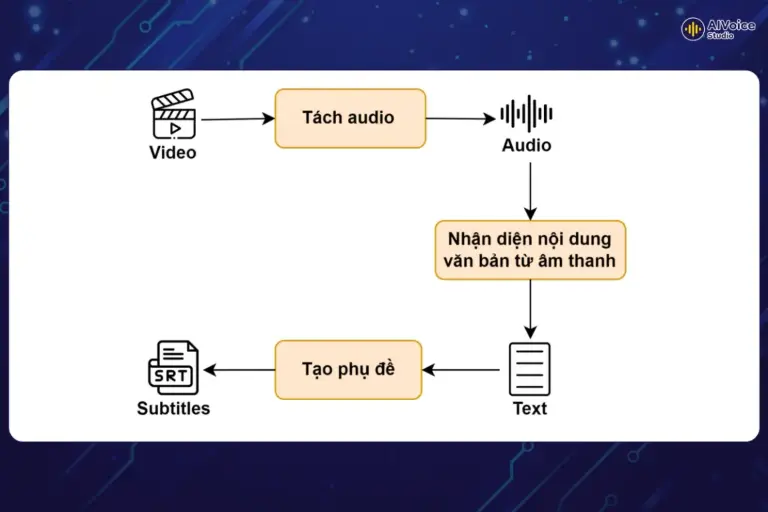
1.1. Tách audio từ video
Quy trình bắt đầu bằng việc tách âm thanh từ video mà người dùng cung cấp. Đây là bước khởi đầu vô cùng quan trọng, bởi việc tách âm thanh không chỉ chuẩn bị dữ liệu đầu vào cần thiết mà còn giúp tối ưu hóa quá trình xử lý tiếp theo. Việc này giúp hệ thống tập trung vào dữ liệu cốt lõi, tiết kiệm thời gian và tài nguyên, đồng thời làm cho việc nhận diện giọng nói nhanh chóng và hiệu quả hơn. m thanh sau khi tách sẽ được dùng để nhận diện nội dung văn bản.
1.2. Nhận diện nội dung văn bản
Sau khi hoàn thành giai đoạn tách âm thanh, bước tiếp theo là sử dụng công nghệ nhận diện giọng nói tự động (ASR) để tự động chuyển đổi nội dung từ âm thanh thành văn bản. Quá trình này bao gồm việc hệ thống kết nối và sử dụng API của các dịch vụ ASR để nhận diện và ghi lại nội dung văn bản từ âm thanh, đồng thời ghi nhận thời điểm xuất hiện của từng từ.

1.3. Tạo các câu phụ đề
Sau khi đã xử lý nhận diện nội dung văn bản, bước tiếp theo là tạo các câu phụ đề từ nội dung nhận diện được. Kết quả từ các dịch vụ ASR thường bao gồm hai phần chính: nội dung và thời gian bắt đầu/kết thúc của từng từ trong đoạn văn bản nhận diện được.
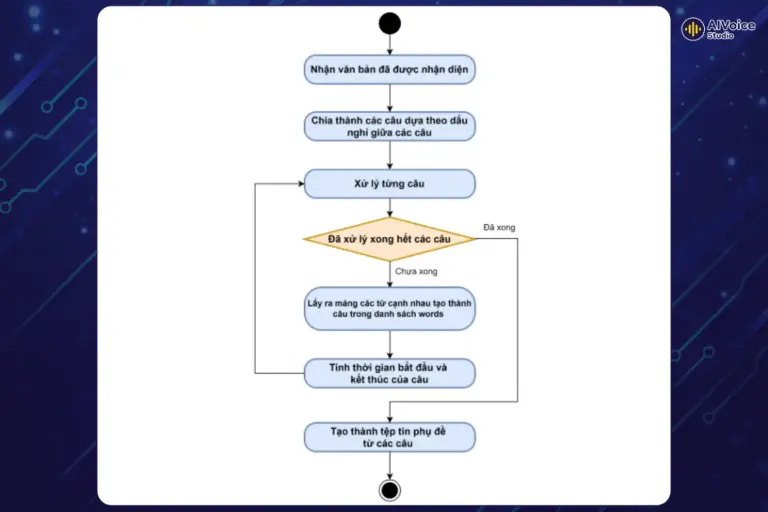
Các câu phụ đề sẽ được chia và xác định theo dấu nghỉ phân cách giữa các câu. Vì vậy, dấu câu là yếu tố quan trọng giúp xác định các điểm kết thúc của một câu hoàn chỉnh. Các dịch vụ ASR hiện nay đều có thể tự động thêm dấu câu vào kết quả nhận diện, tuy nhiên điều này không xảy ra trong tất cả các trường hợp. Vì vậy, cần áp dụng công nghệ LLM để phân tích ngữ cảnh và tự động thêm dấu câu một cách chính xác. Hệ thống sẽ thông qua các hướng dẫn “prompt” để thêm dấu câu vào đoạn văn cung cấp được tạo ra.

So với đoạn văn gốc, kết quả do LLM xử lý sẽ tự động thêm các dấu câu. Các dấu câu được thêm cũng giúp đoạn văn bản rõ nghĩa hơn, các câu được cắt ra cũng đầy đủ nghĩa hơn. Điều này không chỉ cải thiện đáng kể chất lượng và độ chính xác của phụ đề mà còn làm cho chúng trở nên dễ hiểu và tự nhiên hơn khi đọc.
Các câu phụ đề sau đó sẽ được tạo thành tệp tin phụ đề dựa trên cấu trúc tệp phụ đề SRT. Tệp tin này sẽ được lưu trữ trên các dịch vụ lưu trữ đám mây để dễ dàng truy cập và sử dụng để lồng tiếng bằng AI.
2. Dịch phụ đề sang ngôn ngữ mới
Sau khi có được file phụ đề được tạo tự động, bước tiếp theo mà hệ thống cần thực hiện là dịch nội dung phụ đề sang ngôn ngữ mới. Để dịch thuật hiệu quả nhất, cần cải thiện độ chính xác bản dịch và tối ưu hóa quá trình dịch.
2.1 Cải thiện hiệu suất bằng phương pháp xử lý đồng thời
Với số lượng lớn câu phụ đề, việc gộp tất cả các câu lại để dịch cùng một lúc sẽ làm cho quá trình xử lý trở nên chậm chạp và tốn nhiều thời gian. Để đảm bảo quá trình dịch thuật diễn ra nhanh chóng và đạt kết quả tốt, giải pháp tối ưu nhất là xử lý dịch theo lô. Phương pháp này giúp tối ưu hóa tài nguyên và thời gian, đặc biệt khi phải xử lý một lượng lớn nội dung. Quy trình xử lý sẽ bắt đầu khi nhận được danh sách các câu phụ đề. Từ danh sách các câu này, hệ thống sẽ tiến hành xử lý và gộp nhiều câu lại thành từng đoạn văn.
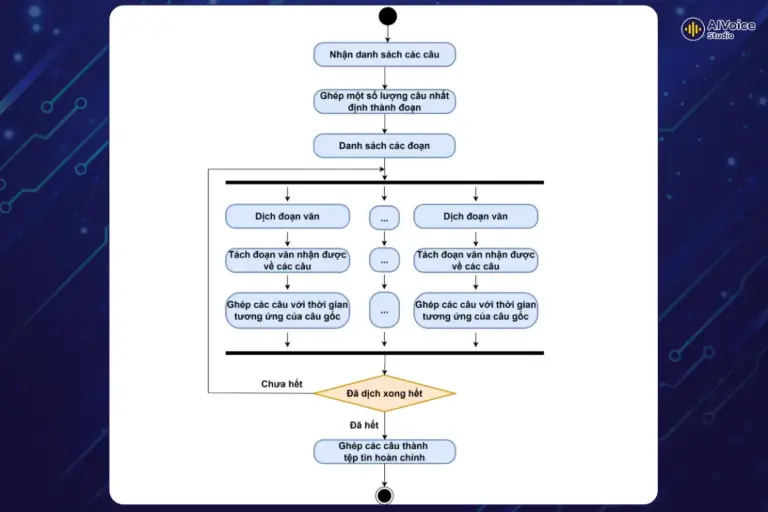
2.2 Cải thiện chất lượng dịch thuật bằng việc cung cấp thêm ngữ cảnh
Để thực hiện dịch theo lô, hệ thống cần xác định số lượng câu sẽ được gộp lại thành một lô. Đối với các API dịch thông thường, số lượng câu gộp lại có thể được điều chỉnh linh hoạt theo nhu cầu cụ thể của từng trường hợp. Sau khi gộp, hệ thống sẽ gọi API để tiến hành dịch. Tuy nhiên, khi sử dụng các API dựa trên mô hình ngôn ngữ lớn (LLM), việc tính toán số lượng câu trong mỗi lô cần được thực hiện kỹ lưỡng.
Các mô hình LLM có khả năng phân tích ngữ cảnh sâu rộng để tạo ra bản dịch chất lượng cao, mượt mà và tự nhiên hơn. Tuy nhiên, điều này có thể dẫn đến sự khác biệt về số lượng câu giữa đoạn văn gốc và bản dịch. Để khắc phục vấn đề này, hệ thống cần thiết kế một prompt đặc biệt sao cho số lượng câu trong kết quả dịch vẫn giữ nguyên như trong văn bản gốc.

Bằng cách này, mô hình LLM sẽ hiểu rằng cần phải duy trì sự phân tách rõ ràng giữa các câu và giữ nguyên thứ tự ban đầu trong bản dịch. Điều này giúp đảm bảo rằng kết quả dịch không chỉ chính xác về mặt ngữ nghĩa mà còn khớp với cấu trúc thời gian của phụ đề gốc.
Sau khi quá trình dịch hoàn tất, các câu dịch mới sẽ được hợp nhất thành một tệp phụ đề hoàn chỉnh. Tệp phụ đề này sẽ chứa đầy đủ thông tin về nội dung và thời gian hiển thị, phù hợp với cấu trúc của các tệp phụ đề chuẩn.
3. Chuyển phụ đề thành giọng nói lồng tiếng
3.1 Tiền xử lý nội dung
Khi nhận được yêu cầu với một tệp phụ đề, bước đầu tiên là đọc tệp để trích xuất các thông tin cần thiết như thời gian hiển thị và nội dung của từng câu phụ đề. Tuy nhiên, phụ đề có thể chứa các ký tự đặc biệt hoặc các đoạn văn không hợp lệ mà hệ thống chuyển văn bản thành giọng nói (Text to Speech) không thể nhận diện và xử lý. Do đó, bước tiền xử lý là cần thiết để loại bỏ các ký tự đặc biệt và chuẩn hóa văn bản, đảm bảo rằng dữ liệu đầu vào phù hợp và sẵn sàng cho hệ thống tổng hợp giọng nói sử dụng.
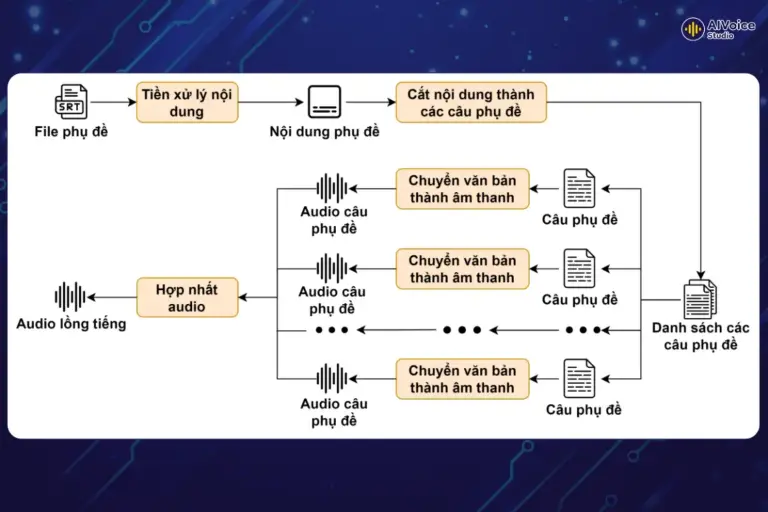
Thông qua các bước tiền xử lý, nội dung phụ đề đã có thể được sử dụng để tiến hành bước tiếp theo.
3.2 Cắt nội dung thành các câu phụ đề
Sau khi có được nội dung sạch, hệ thống sẽ chia nội dung phụ đề thành các câu phụ đề riêng lẻ. Mỗi câu sẽ đi kèm với thông tin chi tiết về giọng đọc, thời gian bắt đầu, thời gian kết thúc và nội dung của phụ đề. Ưu điểm của việc chia nội dung thành từng câu phụ đề:
Chia nhỏ nội dung thành các câu phụ đề giúp hệ thống Text to Speech xử lý hiệu quả hơn, giảm thời gian và tránh quá tải. Kết quả là, chất lượng giọng đọc được cải thiện, giọng điệu và ngữ điệu được điều chỉnh chính xác hơn, tạo ra trải nghiệm nghe tự nhiên và mượt mà hơn cho người dùng.
Việc chia nhỏ và xử lý từng câu cũng giúp hệ thống dễ dàng xác định và khắc phục lỗi nếu có, nâng cao độ chính xác và tin cậy của quá trình chuyển đổi. Hơn nữa, trong trường hợp cần thay đổi hoặc chỉnh sửa phụ đề, việc điều chỉnh trên từng câu cụ thể sẽ dễ dàng và linh hoạt hơn rất nhiều.
3.3 Chuyển văn bản thành âm thanh
Ở bước này, hệ thống sẽ tiến hành chuyển đổi từng câu đã được cắt thành các đoạn âm thanh riêng biệt. Do nội dung đã được chia nhỏ, việc xử lý song song trở nên hiệu quả hơn, giúp tăng tốc độ và đảm bảo độ chính xác. Trong suốt quá trình chuyển đổi, trạng thái và thông tin của từng câu như câu đó đã xử lý xong chưa, thời gian xử lý sẽ được lưu lại để theo dõi và quản lý dễ dàng. Trải nghiệm công cụ chuyển văn bản thành giọng nói lồng tiếng ngay dưới đây:
Đối với các tệp tin phụ đề có kích thước lớn, việc lưu trữ trạng thái từng câu trong cơ sở dữ liệu có thể làm hệ thống chậm chạp do lượng bản ghi lớn. Để giải quyết vấn đề này, việc sử dụng một biến đếm để lưu trữ số lượng câu đã xử lý xong là giải pháp tối ưu nhất. Phương pháp này không chỉ đơn giản mà còn giúp theo dõi tiến độ và quản lý quá trình xử lý hiệu quả hơn rất nhiều.
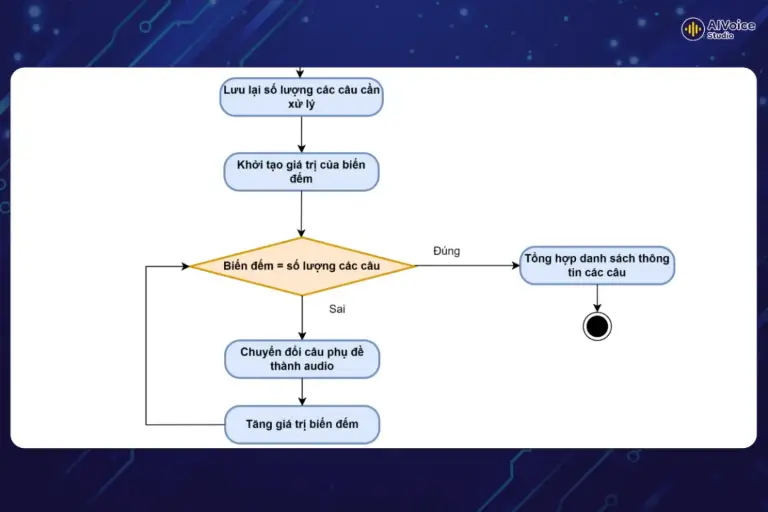
Sau khi hệ thống hoàn tất xử lý tất cả các câu, các đoạn âm thanh kèm theo thông tin chi tiết về từng câu sẽ được chuyển đến bước tiếp theo. Ở đó, chúng sẽ được ghép lại thành một đoạn âm thanh hoàn chỉnh, đúng với vị trí thời gian của từng câu trong văn bản gốc.
3.4 Hợp nhất âm thanh
Cuối cùng, sau khi thu thập các đoạn âm thanh cho từng câu, hệ thống sẽ ghép nối chúng để tạo ra bản ghi âm hoàn chỉnh. Mỗi đoạn âm thanh được căn chỉnh theo thời gian của câu phụ đề, bao gồm cả việc chèn các đoạn nghỉ tự nhiên giữa các câu để đảm bảo sự liền mạch và dễ nghe.
Do số lượng đoạn audio lớn, việc xử lý tuần tự sẽ mất nhiều thời gian và tốn bộ nhớ lưu trữ. Để khắc phục, các đoạn audio sẽ được gộp thành khối và xử lý song song. Mỗi khối bao gồm một số lượng đoạn audio nhất định, cho phép hệ thống tận dụng khả năng xử lý đa nhiệm, từ đó giúp tiết kiệm thời gian và tăng hiệu suất tổng thể của hệ thống.
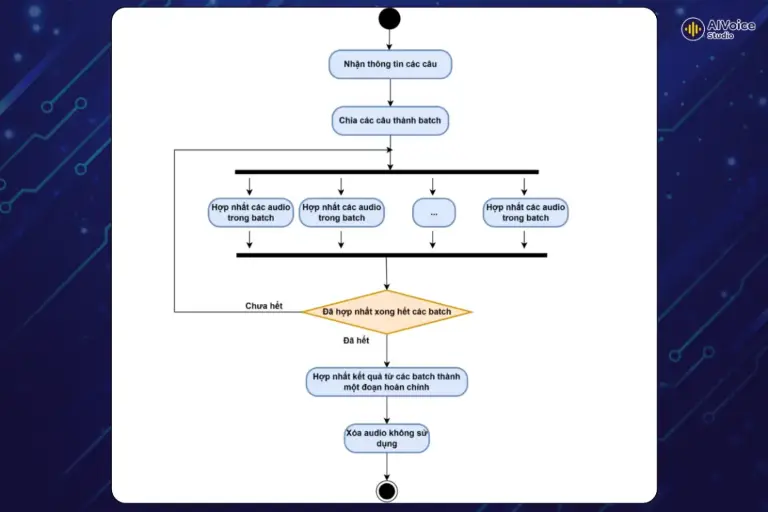
Sau khi xử lý từng khối, hệ thống sẽ gộp các đoạn audio trong từng khối lại với nhau để tạo ra bản ghi âm hoàn chỉnh. Quá trình này đảm bảo âm thanh cuối cùng được xử lý chính xác và chất lượng, đáp ứng nhanh chóng yêu cầu của người dùng.
Như vậy, quá trình chuyển đổi phụ đề thành giọng nói lồng tiếng là một quá trình phức tạp, đòi hỏi sự kết hợp của nhiều công nghệ hiện đại. Từ việc tạo và dịch phụ đề cho đến tổng hợp âm thanh, mỗi bước đều đóng vai trò quan trọng trong việc tạo ra một bản lồng tiếng chất lượng cao. Nhìn về tương lai, với sự tiến bộ không ngừng của công nghệ AI Dubbing, các nhà sáng tạo nội dung hoàn toàn có thể tự động hoá quá trình sản xuất và nhanh chóng tạo ra sản phẩm chất lượng cao, đáp ứng nhu cầu đa dạng trong ngành truyền thông và giải trí.