

Phương pháp tổng hợp giọng nói là một trong những nền tảng hàng đầu phát triển công nghệ Text to Speeech. Bài viết này sẽ phân tích chi tiết từng phương pháp tổng hợp giọng nói cũng như cách thức hoạt động và các mô hình sử dụng.
1. Tổng hợp giọng nói (Speech Synthesis) là gì?
Tổng hợp giọng nói là quá trình chuyển đổi văn bản sang giọng nói dựa trên nền tảng công nghệ AI và áp dụng các thuật toán. Kết quả của việc tổng hợp này là tạo ra âm thanh mô phỏng giống giọng nói như con người từ nguồn dữ liệu văn bản. Công nghệ này được ứng dụng rộng rãi như phần mềm chuyển văn bản thành giọng nói trực tuyến, trợ lý ảo, tổng đài nhân tạo,…
2. Chi tiết 3 phương pháp tiếng hợp giọng nói phổ biến hiện nay
Hiện nay có 3 phương pháp tổng hợp tiếng nói được sử dụng phổ biến trên thế giới: tổng hợp theo từng đoạn (Concatenative Synthesis), tổng hợp tham số (Parametric Synthesis) và tổng hợp dựa trên mô hình End-To-End.
1. Phương pháp ghép nối (Concatenative Synthesis)
Phương pháp ghép nối là một trong các phương pháp tổng hợp giọng nói đầu tiên và vẫn được sử dụng rộng rãi trong các công nghệ TTS nhờ vào khả năng tạo ra giọng nói có chất lượng cao. Phương pháp này hoạt động bằng cách ghép nối các đoạn âm thanh được ghi âm trước để tạo thành lời nói hoàn chỉnh.
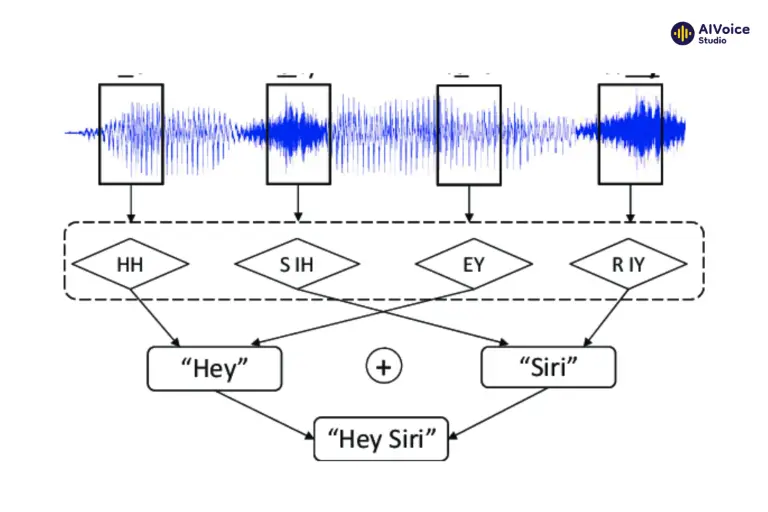
1.1 Dữ liệu đầu vào
Phương pháp ghép nối (Concatenative Synthesis) yêu cầu hai loại dữ liệu chính: dữ liệu âm thanh và dữ liệu văn bản.
1.1.1 Dữ liệu âm thanh
- Đoạn âm thanh ghi âm trước: Cần có các đoạn âm thanh nhỏ như âm vị, âm tiết, từ, hoặc cụm từ được ghi âm từ giọng nói tự nhiên. Những đoạn âm thanh này phải được ghi âm với chất lượng cao, đảm bảo độ rõ ràng và tự nhiên.
- Thông tin chi tiết về âm thanh: Mỗi đoạn âm thanh phải đi kèm với các thông tin chi tiết như đặc điểm âm học (âm sắc, tần số), ngữ điệu và ngữ cảnh sử dụng. Điều này giúp hệ thống lựa chọn và ghép nối các đoạn âm thanh sao cho mượt mà và phù hợp với ngữ cảnh.
1.1.2 Dữ liệu văn bản
- Văn bản đầu vào: Cần có văn bản mà hệ thống sẽ chuyển đổi thành giọng nói. Văn bản này phải được phân tích để xác định các đơn vị âm thanh tương ứng và ngữ điệu cần thiết.
- Thông tin ngữ điệu và ngữ cảnh: Cần có thông tin về ngữ điệu và ngữ cảnh của văn bản để đảm bảo giọng nói tổng hợp không chỉ đúng về mặt ngữ âm mà còn tự nhiên về mặt biểu cảm và ngữ nghĩa.

1.2 Mô hình
Phương pháp ghép nối sử dụng một số mô hình quan trọng để thực hiện quá trình tổng hợp giọng nói. Dưới đây là các mô hình chính được sử dụng:
1.2.1 Mô hình Grapheme-to-Phoneme (G2P)
Đây là quá trình chuyển đổi văn bản thành các ký hiệu âm vị, tức là các đơn vị âm thanh cơ bản của ngôn ngữ. Mô hình này học cách phát âm các từ dựa trên dữ liệu ngữ âm (các ký hiệu âm vị) và văn bản đã được chú thích, giúp hệ thống TTS biết cách phát âm chính xác từng từ trong văn bản đầu vào.
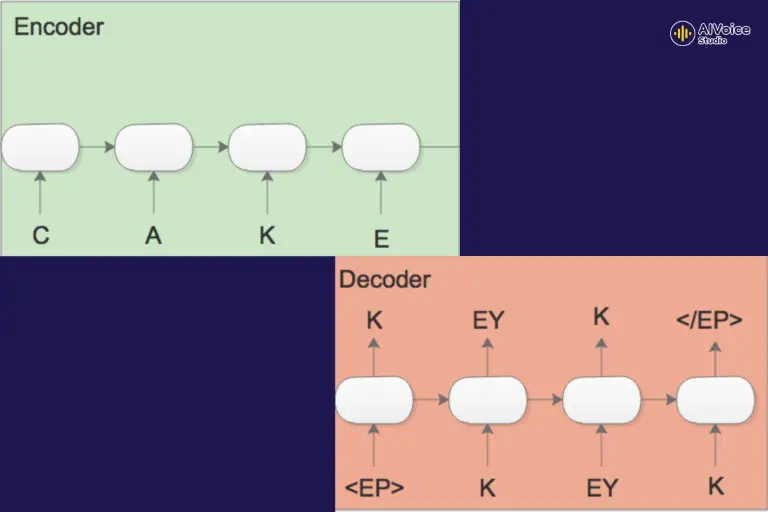
1.2.2 Unit Selection Model
Mô hình chọn các đơn vị âm thanh từ một kho dữ liệu lớn, sao cho khớp với chuỗi phiên âm (các ký hiệu âm vị) đầu vào. Đồng thời đảm bảo rằng sự liên kết giữa các đơn vị âm thanh mượt mà và tự nhiên, giảm thiểu sự ngắt quãng và khác biệt về âm sắc khi các đoạn âm thanh được ghép nối với nhau.
1.2.3 Prosody Matching Model
Mô hình này điều chỉnh ngữ điệu và âm sắc của giọng nói dựa trên ngữ cảnh của câu văn bản. Điều này giúp đảm bảo giọng nói tổng hợp không chỉ đúng về mặt ngữ âm mà còn tự nhiên và dễ nghe về mặt biểu cảm và ngữ nghĩa. Ngữ điệu và âm sắc được điều chỉnh để phù hợp với ý nghĩa và cảm xúc của câu, giúp giọng nói tổng hợp trở nên sinh động và gần gũi hơn với người nghe.
2. Phương pháp tổng hợp dựa trên tham số thống kê (Parametric Synthesis)
Phương pháp tổng hợp tiếng nói dựa trên tham số thống kê (Parametric Synthesis) tạo ra giọng nói bằng cách sử dụng các tham số thống kê để mô phỏng các đặc điểm âm học của giọng nói. Thay vì ghép nối các đoạn âm thanh đã ghi âm trước như phương pháp ghép nối, phương pháp này tổng hợp giọng nói từ các mô hình toán học dựa trên dữ liệu ngữ âm và ngữ điệu đã được phân tích trước đó.
2.1 Dữ liệu
Phương pháp tổng hợp dựa trên tham số thống kê cần có dữ liệu âm thanh chính xác và dữ liệu văn bản được phân tích chi tiết để hỗ trợ quá trình tổng hợp giọng nói tự nhiên.
2.1.1 Dữ liệu văn bản
- Văn bản đầu vào: Văn bản mà hệ thống sẽ chuyển đổi thành giọng nói. Cần có dữ liệu văn bản phong phú để đảm bảo tính đa dạng và chính xác trong tổng hợp giọng nói.
- Thông tin ngữ điệu và ngữ cảnh: Văn bản đầu vào cần đi kèm với thông tin về ngữ điệu và ngữ cảnh để mô hình có thể điều chỉnh giọng nói cho phù hợp, đảm bảo sự tự nhiên và mượt mà trong giọng nói tổng hợp.
2.1.2 Dữ liệu âm thanh
- Đoạn âm thanh ghi âm trước: Cần có các đoạn âm thanh tự nhiên từ giọng nói của con người, ghi âm với chất lượng cao để đảm bảo tính chính xác và tự nhiên của giọng nói tổng hợp.
- Chú thích chi tiết: Các đoạn âm thanh phải được chú thích chi tiết với các ký hiệu âm vị (phonemes) và thông tin ngữ điệu (prosody) như tần số cơ bản, biên độ và phổ. Các chú thích này giúp mô hình học được cách phát âm và ngữ điệu tự nhiên của từng âm vị trong các ngữ cảnh khác nhau.

2.2 Mô hình
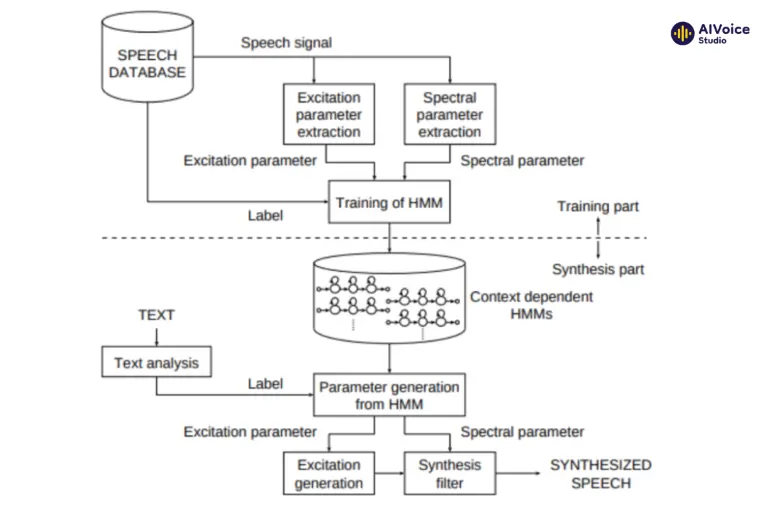
Phương pháp tổng hợp dựa trên tham số thống kê (Parametric Synthesis) sử dụng hai mô hình chính để tạo ra giọng nói từ dữ liệu huấn luyện: Mạng học sâu (Deep Neural Networks – DNN) và Mô hình Hidden Markov Models (HMM).
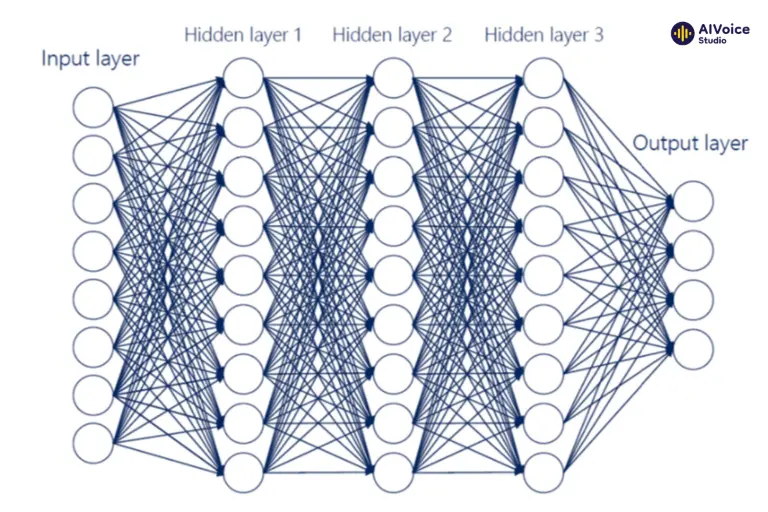
2.2.1 Mạng học sâu (Deep Neural Networks – DNN)
Mạng học sâu (Deep Neural Networks – DNN) học các đặc trưng âm học từ dữ liệu huấn luyện để tạo ra giọng nói tự nhiên và mạch lạc. DNN được huấn luyện trên dữ liệu âm thanh ghi âm trước, học cách các đặc trưng âm học như tần số, biên độ, ngữ điệu, âm sắc và trọng âm biến đổi theo thời gian.
Khi nhận văn bản đầu vào, DNN sử dụng dữ liệu này để dự đoán các tham số âm học cần thiết cho quá trình tổng hợp giọng nói. Nhờ khả năng nắm bắt các mối quan hệ phức tạp giữa các yếu tố âm học, DNN giúp tạo ra giọng nói tự nhiên và biểu cảm hơn. Đồng thời, DNN cũng học cách điều chỉnh ngữ điệu và trọng âm dựa trên ngữ cảnh của câu văn bản, giúp giọng nói tổng hợp trở nên mượt mà và phù hợp với ngữ cảnh sử dụng.
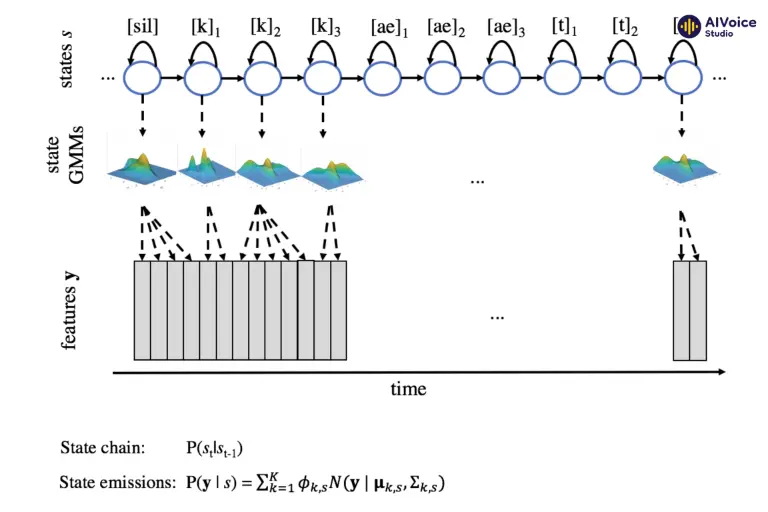
2.2.2 Mô hình Hidden Markov Models (HMM)
Mô hình Hidden Markov Models (HMM) mô phỏng chuỗi âm thanh và học các tham số âm học để tạo ra giọng nói tự nhiên và liên tục. HMM chia giọng nói thành các trạng thái âm học khác nhau, mỗi trạng thái đại diện cho một phần nhỏ của âm thanh.
Mô hình được huấn luyện trên dữ liệu âm thanh ghi âm trước để học các tham số âm học đặc trưng cho từng trạng thái, bao gồm các đặc điểm như phổ tần số và biên độ. Khi tổng hợp giọng nói, HMM sử dụng các tham số âm học này để chuyển đổi liên tục giữa các trạng thái, tạo ra chuỗi âm thanh liên tục và tự nhiên. Điều này giúp giọng nói tổng hợp không bị ngắt quãng, giữ được tính mạch lạc và tự nhiên, góp phần nâng cao chất lượng của giọng nói tổng hợp.
3. Phương pháp tổng hợp tiếng nói hiện đại End-To-End
Phương pháp tổng hợp tiếng nói hiện đại End-To-End là một bước tiến lớn trong lĩnh vực tổng hợp tiếng nói, sử dụng các mô hình học sâu để chuyển đổi trực tiếp từ văn bản thành giọng nói mà không cần qua các bước trung gian như trong các phương pháp truyền thống. Điều này mang lại nhiều lợi ích về hiệu suất, tính chính xác và tự nhiên của giọng nói tổng hợp.
3.1 Dữ liệu
Phương pháp tổng hợp tiếng nói hiện đại End-To-End và phương pháp tổng hợp dựa trên tham số thống kê (Parametric Synthesis) đều sử dụng văn bản và âm thanh làm dữ liệu đầu vào, nhưng có sự khác biệt đáng kể về cách thức xử lý và yêu cầu dữ liệu.
Phương pháp End-To-End đơn giản hơn ở cấp độ đầu vào nhưng yêu cầu lượng dữ liệu lớn hơn để huấn luyện mô hình. Điều này đòi hỏi phải thu thập và chuẩn bị các cặp văn bản và âm thanh tương ứng với độ đa dạng và chất lượng cao. Nếu dữ liệu huấn luyện phong phú và được chuẩn bị cẩn thận, mô hình có thể học các đặc điểm âm thanh tự nhiên và tạo ra giọng nói chân thực. Vì vậy, việc đảm bảo dữ liệu huấn luyện không có lỗi và bao gồm nhiều tình huống khác nhau sẽ giúp mô hình có khả năng tổng hợp tiếng nói với độ chính xác cao và tính linh hoạt, đáp ứng tốt các yêu cầu sử dụng.

3.2 Mô hình
Các mô hình của phương pháp End-to-End trong tổng hợp tiếng nói đã mang lại những cải tiến vượt bậc trong chất lượng và tự nhiên của giọng nói tổng hợp. Có thể kể đến như các mô hình âm học bao gồm FastSpeech, FastSpeech2, FastPitch, Tacotron, Flowtron, LightSpeech, AdaSpeech, VITS,… Hay các mô hình Vocoder bao gồm HifiGAN, WaveGlow, WaveNet, WaveRNN,… Dưới đây là một số mô hình tiêu biểu và cách chúng hoạt động:
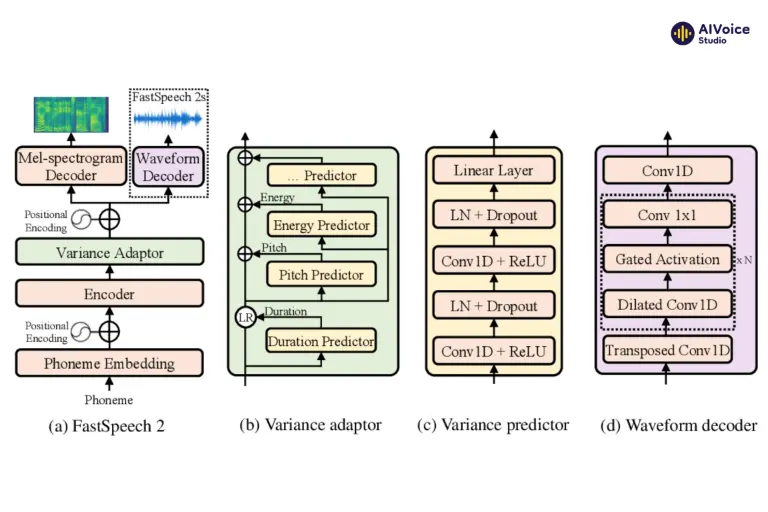
3.2.1 FastSpeech2
- Chuyển đổi đặc trưng âm thanh: FastSpeech2 là một mô hình tổng hợp tiếng nói dựa trên mạng học sâu, có khả năng chuyển đổi các đặc trưng âm thanh đã được giải mã từ văn bản thành các đặc trưng phổ tần số (spectrogram) một cách nhanh chóng và hiệu quả.
- Tốc độ và hiệu quả: FastSpeech2 cải thiện đáng kể tốc độ tổng hợp tiếng nói so với các mô hình trước đây, đồng thời duy trì chất lượng âm thanh cao. Điều này giúp quá trình tổng hợp tiếng nói trở nên nhanh chóng và khả thi cho các ứng dụng thời gian thực.
3.2.2 HiFi-GAN
- Tạo ra âm thanh chất lượng cao: HiFi-GAN là một mô hình mạng đối kháng sinh (GAN) được thiết kế để tạo ra sóng âm thanh từ các đặc trưng phổ tần số với chất lượng cao và độ tự nhiên vượt trội.
- Độ tự nhiên của giọng nói: HiFi-GAN tập trung vào việc tái tạo chi tiết và độ phức tạp của sóng âm thanh, giúp giọng nói tổng hợp trở nên mượt mà và tự nhiên hơn, gần giống với giọng nói thực tế của con người.
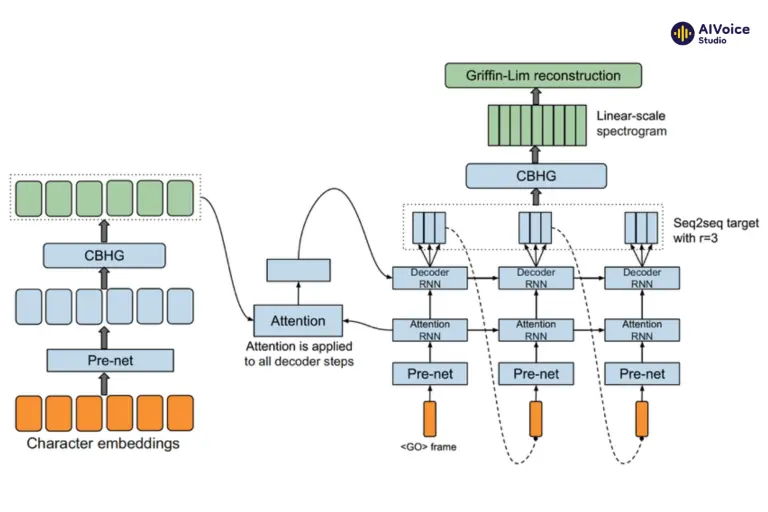
3.2.3 Tacotron
Tacotron là mô hình đầu tiên giới thiệu cách tiếp cận End-to-End cho tổng hợp tiếng nói. Tacotron sử dụng một mạng nơ-ron hồi tiếp (RNN) với cơ chế attention để chuyển đổi văn bản thành các đặc trưng Mel-spectrogram. Sau đó, một mạng nơ-ron tích chập (CNN) chuyển đổi Mel-spectrogram thành dạng sóng âm thanh.
3.2.4 WaveNet
WaveNet là mô hình sinh dạng sóng âm thanh dựa trên mạng nơ-ron tích chập (CNN), được phát triển bởi DeepMind. WaveNet có khả năng tạo ra âm thanh rất tự nhiên bằng cách học trực tiếp từ dữ liệu âm thanh thô. WaveNet thường được sử dụng như một bộ tổng hợp trong các hệ thống tổng hợp tiếng nói End-to-End, như Tacotron 2.
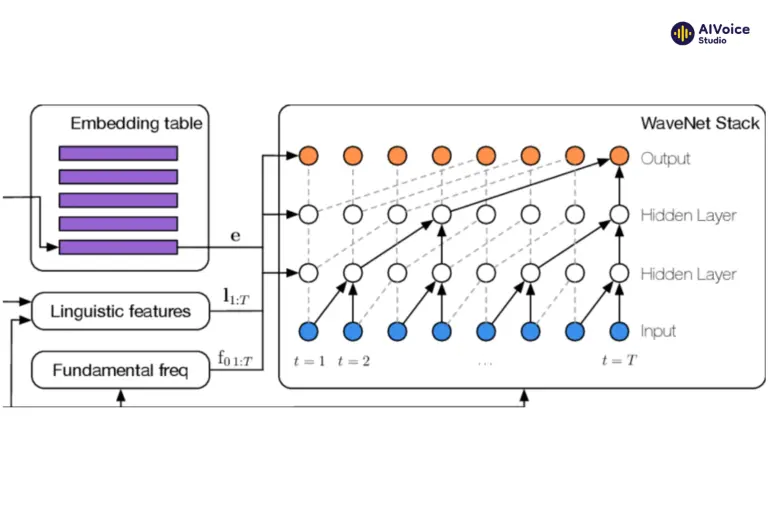
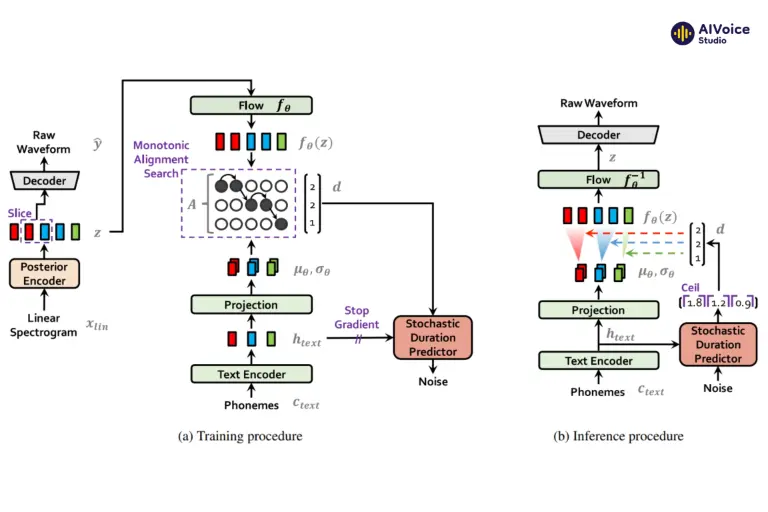
3.2.5 VITS (Variational Inference Text-to-Speech)
VITS là mô hình sử dụng inference biến phân kết hợp với các mạng nơ-ron để tạo ra giọng nói tự nhiên và linh hoạt. VITS học các đặc trưng âm thanh từ văn bản và sử dụng các mẫu ngẫu nhiên để tạo ra các biến thể tự nhiên của giọng nói.
3. Các câu hỏi thường gặp về Tổng hợp giọng nói (Speech Synthesis)
3.1 Tổng hợp tiếng nói (Speech Synthesis) và Text-to-Speech có giống nhau không?
Có. Text-to-Speech (TTS) là ứng dụng cụ thể của Speech Synthesis, tức là một hệ thống chuyển đổi văn bản thành giọng nói. TTS thường được dùng phổ biến trong các sản phẩm thương mại như trợ lý ảo, GPS, tổng đài AI…
3.2 Tại sao cần nhiều phương pháp tổng hợp tiếng nói khác nhau?
Mỗi phương pháp có những ưu – nhược điểm riêng về chất lượng giọng nói, tốc độ xử lý, tài nguyên tính toán và khả năng tùy biến. Chẳng hạn:
- Concatenative: âm thanh tự nhiên, nhưng thiếu linh hoạt
- Parametric: dễ điều chỉnh, nhẹ, nhưng giọng máy
- End-to-End: giọng tự nhiên, tùy biến tốt, nhưng cần dữ liệu lớn và GPU mạnh
3.3 Phương pháp ghép nối (Concatenative Synthesis) hoạt động như thế nào?
Nó ghép các đoạn âm thanh có sẵn (âm tiết, từ, cụm từ) đã được ghi âm trước để tạo thành câu hoàn chỉnh. Hệ thống chọn và nối các đoạn sao cho khớp ngữ cảnh và ngữ điệu, đảm bảo độ trơn tru và tự nhiên.
3.4 Phương pháp tham số (Parametric) khắc phục được gì so với ghép nối?
- Gọn nhẹ hơn, không cần kho âm thanh lớn
- Tùy chỉnh tốt: dễ điều khiển tốc độ, ngữ điệu, biểu cảm
- Tích hợp tốt vào thiết bị nhỏ (như điện thoại, robot)
Tuy nhiên, chất lượng âm thanh thường nghe “máy”, thiếu tự nhiên.
3.5 End-to-End TTS là gì? Tại sao lại được ưa chuộng hiện nay?
End-to-End TTS là phương pháp hiện đại dùng deep learning để chuyển trực tiếp từ văn bản thành sóng âm thanh mà không qua các bước trung gian. Nó cho chất lượng âm thanh:
- Tự nhiên hơn
- Phát âm chính xác hơn
- Có thể học cảm xúc, nhấn nhá, ngữ điệu
Các mô hình phổ biến gồm: FastSpeech2, Tacotron2, VITS, HiFi-GAN.
3.6 Ưu điểm của mô hình FastSpeech2 là gì?
- Tốc độ tổng hợp nhanh gấp nhiều lần Tacotron
- Ổn định hơn: không bị lỗi ngắt câu, phát âm sai
- Dễ huấn luyện và triển khai thực tế
FastSpeech2 thường dùng cùng các vocoder như HiFi-GAN để tạo ra giọng nói mượt và sắc nét.
3.7 Mô hình nào cho giọng nói tự nhiên nhất hiện nay?
Kết hợp:
- Tacotron2 / FastSpeech2 / VITS (cho phần chuyển văn bản → spectrogram)
- HiFi-GAN / WaveNet (cho phần spectrogram → sóng âm thanh)
VITS là một trong những mô hình mới nhất với độ tự nhiên cao + tốc độ tốt.
3.8 Mô hình tổng hợp tiếng nói có thể thể hiện cảm xúc không?
Có. Một số mô hình TTS hiện đại (như VITS, AdaSpeech) có khả năng học biểu cảm như vui, buồn, căng thẳng, lịch sự… Tuy nhiên cần có dữ liệu huấn luyện được gắn nhãn cảm xúc rõ ràng, hoặc bộ điều khiển cảm xúc riêng (emotion embedding).
Công nghệ Text to Speech đã phát triển qua nhiều phương pháp khác nhau, từ Concatenative Synthesis, Parametric Synthesis đến các mô hình học sâu hiện đại. Mỗi phương pháp đều có ưu điểm và nhược điểm riêng, phù hợp với các ứng dụng và yêu cầu khác nhau. Với sự tiến bộ không ngừng của trí tuệ nhân tạo và học sâu, tương lai của công nghệ chuyển văn bản thành giọng nói hứa hẹn sẽ tiếp tục mang lại những cải tiến đáng kể, tạo ra giọng nói nhân tạo ngày càng tự nhiên và chân thực hơn.